
Reasoning (Beta)
Изучите продвинутые модели для решения сложных задач и рассуждения. Модели серии o1 от OpenAI — это новые крупные языковые модели, обученные с помощью подкрепления, чтобы выполнять комплексные умозаключения. Модели o1 формируют внутреннюю цепочку размышлений перед ответом пользователю. Они выделяются в научном рассуждении, занимают 89-й процентиль в соревновательных вопросах по программированию (Codeforces), входят в число 500 лучших студентов в США на отборочном этапе для USA Math Olympiad (AIME) и превосходят уровень точности PhD в задаче по физике, биологии и химии (GPQA).
В API доступны две модели рассуждения:
o1-preview: ранний просмотр нашей моделиo1, предназначенной для решения сложных задач с использованием обширных общих знаний о мире.o1-mini: более быстрая и экономичная версияo1, особенно хорошо подходящая для задач по программированию, математике и науке, где не требуется обширных знаний.
Они предлагают значительные улучшения в рассуждении, но не предназначены для замены GPT-4o во всех случаях.
Если вы создаете приложения, требующие входных изображений, вызова функций или постоянной быстрой реакции, модели GPT-4o и GPT-4o mini остаются предпочтительным выбором. Однако, для приложений, требующих глубокого анализа и готовых к более длинным временам ответа, модели o1 могут стать отличным выбором. Мы рады увидеть, что вы создадите с их помощью!
Модели o1 в настоящее время находятся в бета-версии с ограниченными возможностями. Доступ ограничен только некоторым уровням использования (проверьте ваш уровень использования здесь), с низкими лимитами частоты запросов. Мы работаем над расширением функций, увеличением лимитов и предоставлением доступа большему количеству разработчиков в ближайшие недели!
Быстрый старт
И модели o1-preview, и o1-mini доступны через конечную точку завершения чата.
Использование модели o1-preview с Python
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": (
"Напишите скрипт bash, который принимает матрицу,"
"представленную в виде строки с форматом '[1,2],[3,4],[5,6]',"
"и выводит транспонированную матрицу в том же формате."
)
}
]
)
print(response.choices[0].message.content)import OpenAI from "openai";
const openai = new OpenAI();
const completion = await openai.chat.completions.create({
model: "o1-preview",
messages: [
{
role: "user",
content: "Напишите скрипт bash, который принимает матрицу, "
+ "представленную в виде строки с форматом '[1,2],[3,4],[5,6]', "
+ "и выводит транспонированную матрицу в том же формате."
}
]
});
console.log(completion.choices[0].message.content);curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "o1-preview",
"messages": [
{
"role": "user",
"content": "Напишите скрипт bash, который принимает матрицу, "
+ "представленную в виде строки с форматом \"[1,2],[3,4],[5,6]\", "
+ "и выводит транспонированную матрицу в том же формате."
}
]
}'Бета-ограничения
Во время бета-теста многие параметры API завершения чата еще не доступны. В первую очередь:
- Модальности: только текст, изображения не поддерживаются.
- Типы сообщений: только сообщения пользователя и помощника, системные сообщения не поддерживаются.
- Стриминг: не поддерживается.
- Инструменты: инструменты, вызов функций и параметры формата ответа не поддерживаются.
- Logprobs: не поддерживаются.
- Другое: параметры
temperature,top_pиnзафиксированы на1, в то время какpresence_penaltyиfrequency_penaltyзафиксированы на0. - Ассистенты и Пакетная обработка: эти модели не поддерживаются в API помощников или API пакетной обработки.
Мы будем добавлять поддержку для некоторых из этих параметров в ближайшие недели, когда будем выходить из бета. Такие функции, как мультимодальность и использование инструментов, будут включены в будущие модели серии o1.
Как работает рассуждение
Модели o1 вводят в обращение рейзенинг-токены. Они используют эти токены для "размышлений", разрывая понимание задачи и рассматривая несколько подходов к её решению. После формирования reasoning токенов, модель выдает ответ видимыми tokens завершения и удаляет reasoning токены из своего контекста.
Пример многоходового диалога между пользователем и помощником. Входные и выходные токены каждого шага сохраняются, в то время как reasoning токены отбрасываются.
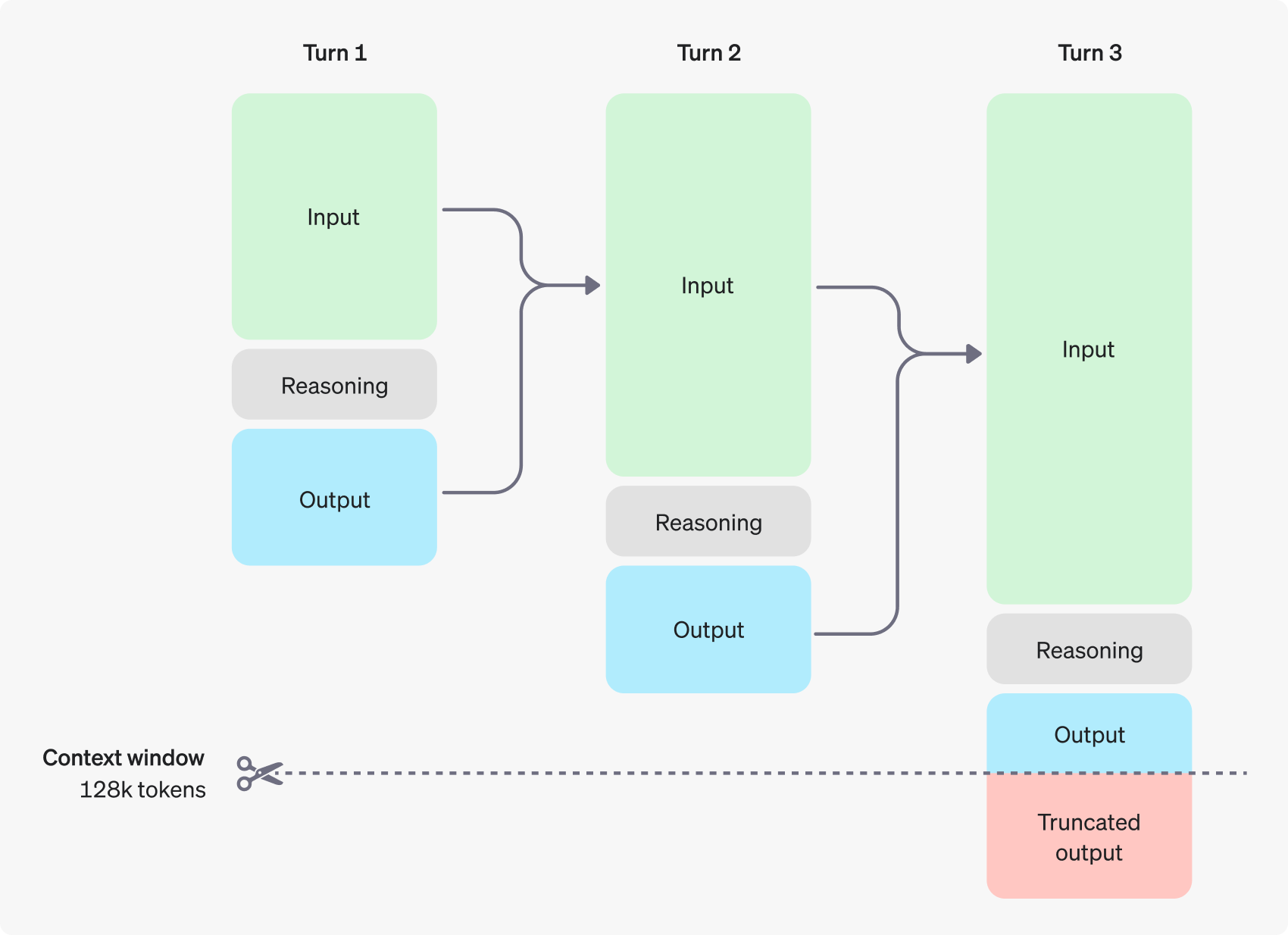
Важные моменты:
- Reasoning токены не сохраняются в контексте API, но занимают место в окне контекста модели и учитываются как выходные токены.
Управление окном контекста
Модели o1-preview и o1-mini предлагают контекстное окно размером 128,000 токенов. У каждого завершения есть верхний предел на количество выходных токенов — это включает в себя как невидимые reasoning токены, так и видимые completion токены. Ограничения по максимальному количеству выходных токенов следующие:
o1-preview: до 32,768 токеновo1-mini: до 65,536 токенов
Важно обеспечить достаточно места для reasoning токенов в окне контекста при создании завершений. В зависимости от сложности задачи модели могут генерировать от нескольких сотен до десятков тысяч reasoning токенов. Точное количество reasoning токенов видно в объекте usage объекта ответа завершения чата, в разделе completion_tokens_details:
Использование завершений чата
{
"usage": {
"total_tokens": 1000,
"prompt_tokens": 400,
"completion_tokens": 600,
"completion_tokens_details": {
"reasoning_tokens": 500
}
}
}Контроль затрат
Чтобы управлять расходами с моделями серии o1, вы можете ограничить общее количество токенов, которые модель генерирует (включая reasoning и completion токены) с помощью параметра max_completion_tokens.
В предыдущих моделях параметр max_tokens управлял как количеством сгенерированных токенов, так и количеством токенов, видимых для пользователя, которые всегда были равны. Однако с серией o1, общее количество сгенерированных токенов может превышать видимые токены из-за внутренних reasoning токенов.
Поскольку некоторые приложения могут полагаться на совпадение max_tokens с количеством полученных токенов от API, серия o1 вводит max_completion_tokens для явного управления общим количеством сгенерированных токенов, включая reasoning и видимые completion токены. Этот явный opt-in гарантирует, что ни одно из существующих приложений не будет нарушено при использовании новых моделей. Параметр max_tokens продолжает функционировать как раньше для всех предыдущих моделей.
Выделение места для reasoning
Если сгенерированные токены достигают допустимого размера окна контекста или заданного вами значения max_completion_tokens, вы получите ответ завершения чата с finish_reason, установленным на length. Это может произойти прежде чем будут созданы видимые completion токены, что может повлечь за собой расходы на ввод и reasoning токены без получения видимого ответа.
Чтобы предотвратить это, убедитесь, что есть достаточное пространство в окне контекста, или установите max_completion_tokens на более высокое значение. OpenAI рекомендует зарезервировать по крайней мере 25,000 токенов для reasoning и выходов в начале экспериментов с этими моделями. По мере того, как вы будете знакомиться с количеством reasoning токенов, необходимых для ваших запросов, вы сможете скорректировать этот резерв.
Советы по составлению промтов
Эти модели работают лучше всего с прямыми промтами. Некоторые техники инженерии промтов, такие как подсказки на основе нескольких примеров или инструкции шаг за шагом, могут не повышать производительность и иногда даже мешать. Вот несколько лучших практик:
- Держите промты простыми и прямыми: Модели отлично понимают и отвечают на краткие, четкие инструкции без необходимости в обширных руководствах.
- Избегайте промтов с цепочкой мыслей: Поскольку эти модели выполняют рассуждения внутренне, подталкивать их думать шаг за шагом или объяснять свое решение нет необходимости.
- Используйте дилеммы для ясности: Используйте такие обозначения, как тройные кавычки, XML теги или заголовки секций, чтобы четко обозначить разные части ввода, помогая модели правильно интерпретировать отличающиеся разделы.
- Ограничивайте дополнительный контекст в Retrieval-Augmented Generation (RAG): При предоставлении дополнительного контекста или документов включайте только наиболее релевантную информацию, чтобы избежать усложнения ответа модели.
Примеры промтов
Кодирование (рефакторинг)
Модели серии o1 от OpenAI могут реализации сложные алгоритмы и писать код. Этот промт просит модель o1 переформатировать компонент React на основе определенных условий.
from openai import OpenAI
client = OpenAI()
prompt = """
Instructions:
- Given the React component below, change it so that nonfiction books have red
text.
- Return only the code in your reply
- Do not include any additional formatting, such as markdown code blocks
- For formatting, use four space tabs, and do not allow any lines of code to
exceed 80 columns
const books = [
{ title: 'Dune', category: 'fiction', id: 1 },
{ title: 'Frankenstein', category: 'fiction', id: 2 },
{ title: 'Moneyball', category: 'nonfiction', id: 3 },
];
export default function BookList() {
const listItems = books.map(book =>
<li>
{book.title}
</li>
);
return (
<ul>{listItems}</ul>
);
}
"""
response = client.chat.completions.create(
model="o1-mini",
messages=[
{
"role": "user",
"content": {
"type": "text",
"text": prompt
}
}
]
)
print(response.choices[0].message.content)Кодирование (планирование)
Модели серии o1 также превосходно справляются с созданием пошаговых планов. В этом примере промт просит o1 создать структуру файловой системы для полного решения, а также Python-код, реализующий требуемый сценарий.
from openai import OpenAI
client = OpenAI()
prompt = """
I want to build a Python app that takes user questions and looks them up in a
database where they are mapped to answers. If there is close match, it retrieves
the matched answer. If there isn't, it asks the user to provide an answer and
stores the question/answer pair in the database. Make a plan for the directory
structure you'll need, then return each file in full. Only supply your reasoning
at the beginning and end, not throughout the code.
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": {
"type": "text",
"text": prompt
}
}
]
)
print(response.choices[0].message.content)Научные исследования
Модели серии o1 от OpenAI зарекомендовали себя в области STEM исследований. Промты, запрашивающие помощь в базовых научных исследованиях, должны показывать сильные результаты.
from openai import OpenAI
client = OpenAI()
prompt = """
What are three compounds we should consider investigating to advance research
into new antibiotics? Why should we consider them?
"""
response = client.chat.completions.create(
model="o1-preview",
messages=[
{
"role": "user",
"content": prompt
}
]
)
print(response.choices[0].message.content)Теперь у вас есть формирование сложных запросов и контроль затрат на использование современных моделей AI. Эти концепции помогут в дальнейших экспериментах и внедрении высокотехнологичных решений в ваши проекты!