
Embeddings
Научитесь преобразовывать текст в числа, раскрывая такие возможности, как поиск.
Новые модели встраивания
text-embedding-3-small и text-embedding-3-large, наши самые новые и производительные модели встраивания, теперь доступны с более низкими затратами, улучшенной многоязычной производительностью и новыми параметрами для управления общим размером.
Что такое встраивания?
Текстовые встраивания OpenAI измеряют связанность текстовых строк. Встраивания обычно используются для:
- Поиска (где результаты оцениваются по релевантности к запросу).
- Кластеризации (где текстовые строки группируются по сходству).
- Рекомендаций (где рекомендуются элементы с похожими текстовыми строками).
- Обнаружения аномалий (где выявляются выбросы с низкой связанностью).
- Измерения разнообразия (где анализируется распределение сходства).
- Классификации (где текстовые строки классифицируются по наиболее похожей метке).
Встраивание — это вектор (список) чисел с плавающей запятой. Дистанция между двумя векторами измеряет их связанность. Маленькие дистанции указывают на высокую связанность, большие дистанции — на низкую.
Посетите нашу страницу ценообразования, чтобы узнать о стоимости встраиваний. Запросы тарифицируются на основе количества токенов во входных данных.
Как получить встраивания
Чтобы получить встраивание, отправьте свою текстовую строку на конечную точку API встраиваний вместе с названием модели встраивания (например, text-embedding-3-small). Ответ будет содержать встраивание (список чисел с плавающей запятой), которое вы можете извлечь, сохранить в векторной базе данных и использовать для множества различных случаев:
Пример: Получение встраиваний с использованием Python
from openai import OpenAI
client = OpenAI()
response = client.embeddings.create(
input="Your text string goes here",
model="text-embedding-3-small"
)
print(response.data[0].embedding)curl https://api.openai.com/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"input": "Your text string goes here",
"model": "text-embedding-3-small"
}'import OpenAI from "openai";
const openai = new OpenAI();
async function main() {
const embedding = await openai.embeddings.create({
model: "text-embedding-3-small",
input: "Your text string goes here",
encoding_format: "float",
});
console.log(embedding);
}
main();Ответ будет содержать вектор встраивания вместе с некоторыми дополнительными метаданными.
Пример ответа встраивания в формате JSON
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
-0.006929283495992422,
-0.005336422007530928,
... (опущено для компактности)
-4.547132266452536e-05,
-0.024047505110502243
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 5,
"total_tokens": 5
}
}По умолчанию длина вектора встраивания будет 1536 для text-embedding-3-small или 3072 для text-embedding-3-large. Вы можете уменьшить размерности встраивания, используя параметр dimensions без потери свойств представления концепции. Мы более подробно рассмотрим размеры встраивания в разделе использования встраиваний.
Модели встраивания
OpenAI предлагает две мощные модели встраивания третьего поколения (обозначенные -3 в идентификаторе модели). Вы можете прочитать сообщение в блоге с анонсом встраивания v3 для получения более подробной информации.
Использование тарифицируется за входной токен, ниже приведен пример стоимости страниц текста в долларах США (предполагая ~800 токенов на страницу):
| Модель | ~ Страниц на доллар | Производительность на MTEB | Макс. ввод |
|---|---|---|---|
text-embedding-3-small | 62,500 | 62.3% | 8191 |
text-embedding-3-large | 9,615 | 64.6% | 8191 |
text-embedding-ada-002 | 12,500 | 61.0% | 8191 |
Примеры использования
Здесь мы показываем некоторые из типов использования. Мы будем использовать набор данных Amazon для обзора продуктов питания для следующих примеров.
Для получения встраиваний мы используем 1,000 самых последних отзывов. Обзоры на английском языке и, как правило, являются либо положительными, либо отрицательными. Каждый отзыв имеет ProductId, UserId, Score, заголовок отзыва (Summary) и основной текст отзыва (Text). Например:
| Product Id | User Id | Score | Summary | Text |
|---|---|---|---|---|
| B001E4KFG0 | A3SGXH7AUHU8GW | 5 | Good Quality Dog Food | I have bought several of the Vitality canned... |
| B00813GRG4 | A1D87F6ZCVE5NK | 1 | Not as Advertised | Product arrived labeled as Jumbo Salted Peanut... |
Мы объединим заголовок отзыва и основной текст в единый текст. Модель закодирует этот текст и выдаст один вектор встраивания.
Получение встраиваний из набора данных
from openai import OpenAI
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
df['ada_embedding'] = df.combined.apply(lambda x: get_embedding(x, model='text-embedding-3-small'))
df.to_csv('output/embedded_1k_reviews.csv', index=False)Чтобы загрузить данные из сохраненного файла, выполните следующий код:
import pandas as pd
df = pd.read_csv('output/embedded_1k_reviews.csv')
df['ada_embedding'] = df.ada_embedding.apply(eval).apply(np.array)Ответы на вопросы с использованием поиска на основе встраиваний
response = client.chat.completions.create(
messages=[
{'role': 'system', 'content': 'You answer questions about the 2022 Winter Olympics.'},
{'role': 'user', 'content': query},
],
model=GPT_MODEL,
temperature=0,
)
print(response.choices[0].message.content)Поиск текста с использованием встраиваний
Для извлечения наиболее релевантных документов мы используем косинусное сходство между векторами встраиваний запроса и каждого документа и возвращаем документы с наибольшими результатами.
from openai.embeddings_utils import get_embedding, cosine_similarity
def search_reviews(df, product_description, n=3, pprint=True):
embedding = get_embedding(product_description, model='text-embedding-3-small')
df['similarities'] = df.ada_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_reviews(df, 'delicious beans', n=3)Поиск кода с использованием встраиваний
Поиск кода работает аналогично поиску текста на основе встраиваний. Мы предоставляем метод извлечения функций Python из всех файлов Python в данном репозитории. Каждая функция затем индексируется моделью text-embedding-3-small.
from openai.embeddings_utils import get_embedding, cosine_similarity
df['code_embedding'] = df['code'].apply(lambda x: get_embedding(x, model='text-embedding-3-small'))
def search_functions(df, code_query, n=3, pprint=True, n_lines=7):
embedding = get_embedding(code_query, model='text-embedding-3-small')
df['similarities'] = df.code_embedding.apply(lambda x: cosine_similarity(x, embedding))
res = df.sort_values('similarities', ascending=False).head(n)
return res
res = search_functions(df, 'Completions API tests', n=3)Рекомендации с использованием встраиваний
Так как меньшие расстояния между векторами встраивания указывают на большее сходство, встраивания могут быть полезны для рекомендаций.
def recommendations_from_strings(
strings: List[str],
index_of_source_string: int,
model="text-embedding-3-small",
) -> List[int]:
"""Return nearest neighbors of a given string."""
# get embeddings for all strings
embeddings = [embedding_from_string(string, model=model) for string in strings]
# get the embedding of the source string
query_embedding = embeddings[index_of_source_string]
# get distances between the source embedding and other embeddings (function from embeddings_utils.py)
distances = distances_from_embeddings(query_embedding, embeddings, distance_metric="cosine")
# get indices of nearest neighbors (function from embeddings_utils.py)
indices_of_nearest_neighbors = indices_of_nearest_neighbors_from_distances(distances)
return indices_of_nearest_neighborsВизуализация данных в 2D
Размер встраиваний варьируется в зависимости от сложности основной модели. Чтобы визуализировать эти высокоразмерные данные, мы используем алгоритм t-SNE для преобразования данных в двумерные.
Мы оцениваем отдельные отзывы в соответствии со звездным рейтингом, присвоенным рецензентом:
- 1 звезда: красный
- 2 звезды: темно-оранжевый
- 3 3 звезды: золотая
- 4-звездочный отель: бирюзовый
- 5-звездочный: темно-зеленый
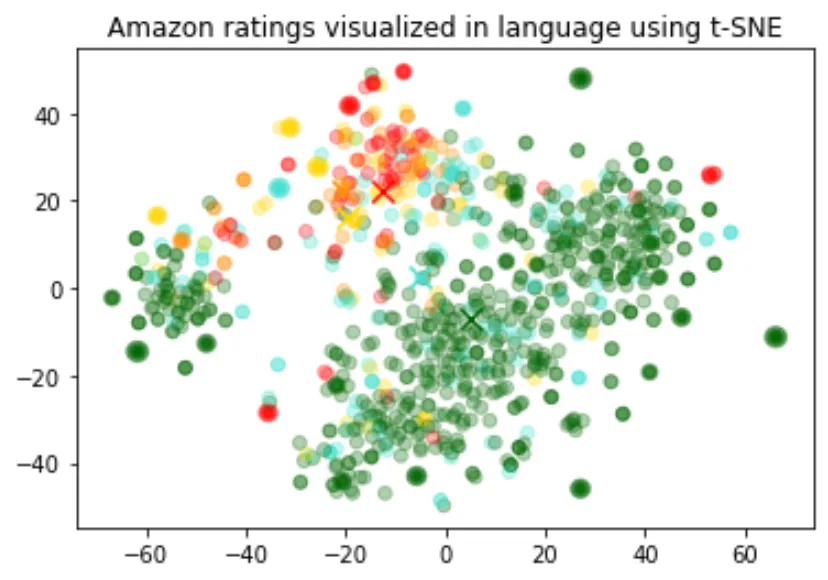
import pandas as pd
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
import matplotlib
df = pd.read_csv('output/embedded_1k_reviews.csv')
matrix = df.ada_embedding.apply(eval).to_list()
# Create a t-SNE model and transform the data
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
vis_dims = tsne.fit_transform(matrix)
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
color_indices = df.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
plt.title("Визуализация рейтингов на Amazon с использованием t-SNE")Встраивание как текстовый кодировщик признаков для алгоритмов машинного обучения
Встраивание можно использовать как общий кодировщик признаков свободного текста в модели машинного обучения. Интеграция встраиваний улучшит производительность любой модели машинного обучения, если некоторые из релевантных входных данных являются свободным текстом. Встраивание также можно использовать как кодировщик категориальных признаков в модели машинного обучения. Это добавляет большую ценность, если имена категориальных переменных имеют значение и многочисленны, например, названия должностей.
Мы наблюдали, что представление встраивания обычно очень насыщенное и информации плотное. Например, сокращение размеров входных данных с помощью SVD или PCA, даже на 10%, обычно приводит к ухудшению производительности на отдельных задачах.
Это кода раздельно делит данные на обучающий набор и тестовый набор, который будет использоваться в следующих двух случаях использования, а именно — регрессией и классификацией.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
list(df.ada_embedding.values),
df.Score,
test_size=0.2,
random_state=42
)Регрессия с использованием признаков встраивания
Встраивания представляют собой изящный способ прогнозирования числового значения. В этом примере мы предсказываем рейтинг в звездах отзыва, основываясь на тексте отзыва. Так как семантическая информация, содержащаяся в встраиваниях, высока, прогноз приличный даже с очень небольшим количеством отзывов.
Мы предполагаем, что оценка является непрерывной переменной между 1 и 5 и позволяет алгоритму предсказать любое число с плавающей запятой. Алгоритм машинного обучения минимизирует расстояние предсказанного значения до истинной оценки и достигает средней абсолютной ошибки 0,39, что означает, что в среднем прогноз отклоняется менее чем на половину звезды.
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators=100)
rfr.fit(X_train, y_train)
preds = rfr.predict(X_test)Классификация с использованием признаков встраивания
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, accuracy_score
clf = RandomForestClassifier(n_estimators=100)
clf.fit(X_train, y_train)
preds = clf.predict(X_test)Классификация без обучающих данных (Zero-shot)
Мы можем использовать встраивания для классификации без обучающих данных. Для каждой категории мы создаем встраивание по имени класса или краткому описанию класса. Чтобы классифицировать новый текст без обучения, мы сравниваем его встраивание со всеми встраиваниями классов и предсказываем класс с наивысшим сходством.
from openai.embeddings_utils import cosine_similarity, get_embedding
df= df[df.Score!=3]
df['sentiment'] = df.Score.replace({1:'negative', 2:'negative', 4:'positive', 5:'positive'})
labels = ['negative', 'positive']
label_embeddings = [get_embedding(label, model=model) for label in labels]
def label_score(review_embedding, label_embeddings):
return cosine_similarity(review_embedding, label_embeddings[1]) - cosine_similarity(review_embedding, label_embeddings[0])
prediction = 'positive' if label_score('Sample Review', label_embeddings) > 0 else 'negative'Получение встраиваний пользователей и продуктов для рекомендательной системы
Мы можем получить встраивание пользователя, усреднив все его отзывы. Аналогично, мы можем получить встраивание продукта, усреднив все отзывы о нем. Для демонстрации полезности этого подхода мы используем подмножество из 50 тыс. отзывов, чтобы охватить большее количество отзывов на пользователя и продукт.
Мы оцениваем полезность этих встраиваний на отдельном тестовом наборе, где анализируем сходство встраивания пользователя и продукта в зависимости от рейтинга. Интересно, что, используя этот подход, даже до того как пользователь получит продукт, можно лучше предсказать, удовлетворит ли он ожидания.
Группировка
Группировка является способом осмысления большого объема текстовых данных. Встраивания полезны для этой задачи, так как они предоставляют семантически значимые векторные представления каждого текста. Так, в неспецифичном методе, группировка выявит скрытые группы в нашем наборе данных.
В этом примере мы обнаруживаем четыре различные группы: одна сосредотачивается на корме для собак, одна — на отрицательных отзывах, и две — на положительных отзывах.
Часто задаваемые вопросы
Как узнать, сколько токенов содержит строка, перед её встраиванием?
В Python вы можете разбить строку на токены с помощью токенайзера OpenAI tiktoken.
Пример кода:
import tiktoken
def num_tokens_from_string(string: str, encoding_name: str) -> int:
"""Возвращает количество токенов в текстовой строке."""
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
num_tokens_from_string("tiktoken is great!", "cl100k_base")Для моделей встраивания третьего поколения, таких как text-embedding-3-small, используйте кодировку cl100k_base.
Больше подробностей и примеров кода можно найти в руководстве OpenAI Cookbook, как учитывать токены с помощью tiktoken.
Как быстро получить K ближайших встраивающих векторов?
Для быстрого поиска по множеству векторов мы рекомендуем использовать векторные базы данных. Вы можете найти примеры работы с векторными базами данных и API OpenAI в нашем Cookbook на GitHub.
Какую функцию расстояния я должен использовать?
Мы рекомендуем косинусное сходство. Выбор функции расстояния обычно не имеет большого значения.
Встраивания OpenAI нормализованы до длины 1, что означает:
- Косинусное сходство можно посчитать чуть быстрее, используя просто произведение векторов.
- Косинусное сходство и евклидово расстояние дадут одинаковый результат в ранжировании.
Могу ли я делиться своими встраиваниями в интернете?
Да, клиенты владеют своими входными и выходными данными из наших моделей, включая случай с встраиваниями. Вы несёте ответственность за то, чтобы содержание, которое вы вводите в наш API, не нарушало какие-либо применимые законы или наши Условия использования.
Знают ли модели встраивания V3 о недавних событиях?
Нет, модели text-embedding-3-large и text-embedding-3-small не знают о событиях, произошедших после сентября 2021 года. Это обычно не является столь серьезным ограничением, как для моделей генерации текста, но в некоторых крайних случаях это может снизить производительность.